







在本系列的“Part 1”中,我们讨论了数据科学和数字主线的关系,本文“Part 2”我们将讨论如何将这些想法付诸实践,我们可以分三步来看。
NO.1
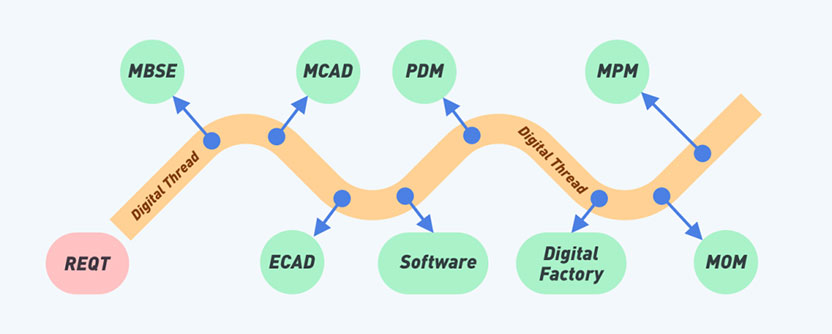
首先,显然是模型和数据。如何将产品生命周期中不同系统数据在Digital Thread上能够被探索,并建立产品数据血缘关系。为此,您可以使用JWI Digital Thread(图1)所示的语义模型定义工具。通过它可以构建领域语义模型和跨领域语义关系,从而驱动连接不同的领域数据存储库。
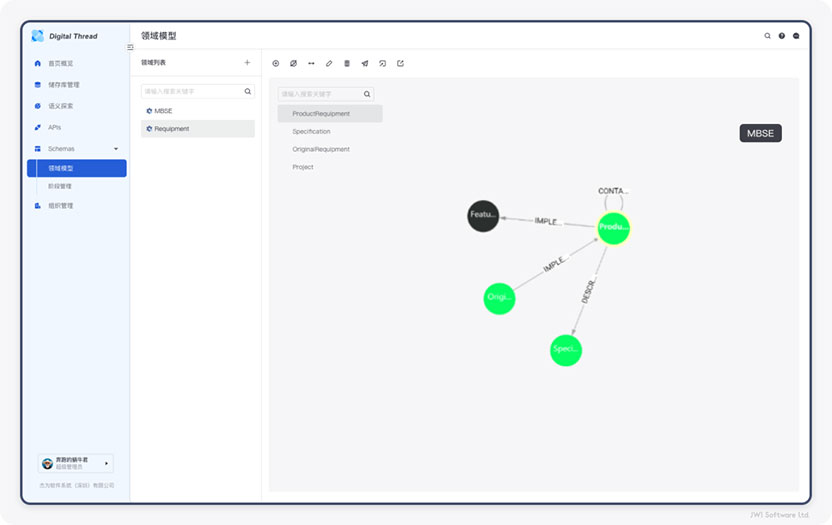
图1:JWI Digital Thread Semantic Schema Modeler
您可以通过JWI Digital Thread语义建模工具构建并管理(图2)所示的工程应用程序中的数据模型,定义它们之间的跨领域语义关系——定义Inter Model Connection;以及各种格式的结构化数据,如:XML、SQL、CSV、JSON、等。
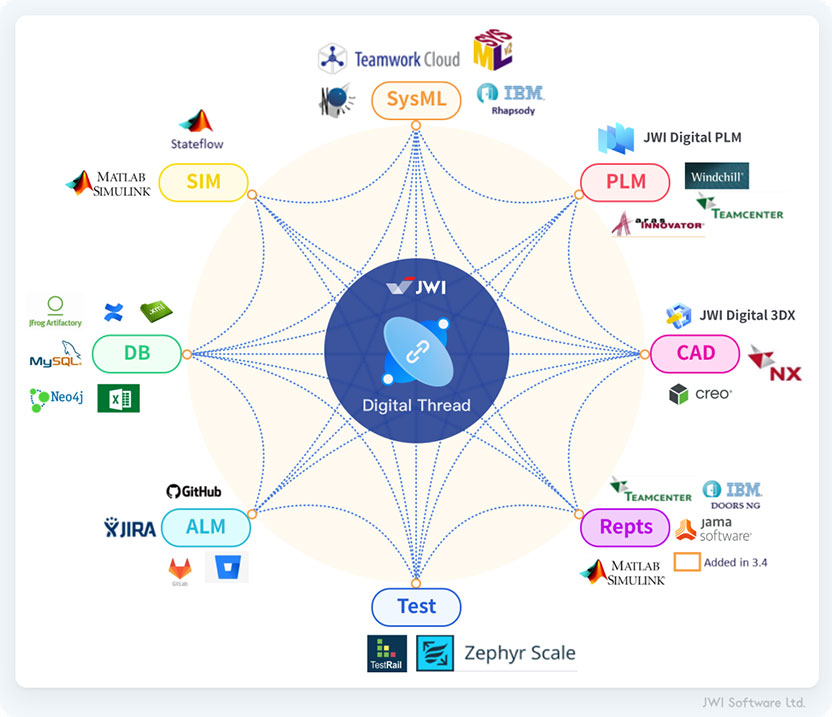
图2:Semantic Schema Driven Connection IN JWI Digital Thread
对数据科学来说,好消息是所有这些数据都是结构化的, 坏消息是分布在不同系统的数据架构存在大量的差异。
NO.2
我们的第二个需求是构建一个通用的抽象模型,所有领域模型均基于抽象模型扩展,允许数据科学家跨整个产品生命周期组织、关联、分析数据集。JWI Digital Thread抽象模型即满足语义模型表达、存储,同时遵循Sys ML2.0 Kernel 和 System Modeling Language规范,所有产品生命周期领域数据均可被适配为(图3)中的抽象模型中。
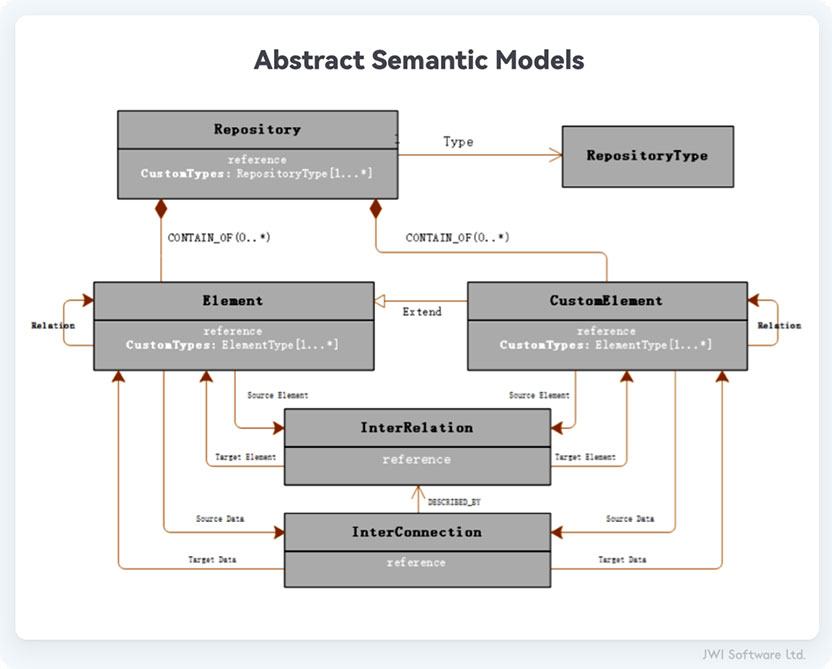
图3:Abstract Semantic Model IN JWI Digital Thread
NO.3
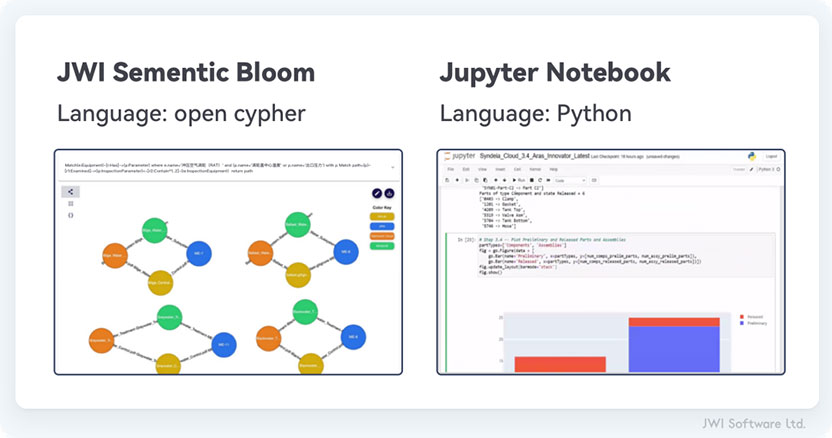
第三,数据分析工具。JWI Digital Thread的目标是提供Schema驱动数据接入的同时,让数据科学家使用他们已知和喜爱的数据分析工具。 本文讨论两种广泛使用的开源数据科学工具,基于Open Cypher的产品数据Bloom(杰为在Open Cypher的标准上自主研发)和Jupyter notebook(图3)。
Open Cypher是属性图数据库最广泛采用的,完全指定的开放查询语言,它提供了一种直观的方式来处理当前的属性图,是ISO正在开发的图形查询语言(GQL)标准的最佳入口。
Jupyter Notebook,这是一个基于网络的交互式计算笔记本,于2014年出现在iPython开源项目中。它由一组有序的单元格组成,包含API调用、计算、文本和可视化,还有许多开源的数据科学库。 您可以使用数据科学计算库分析、探索数据集,当然它也支持其他语言。
本文共分为5个部分,在接下的文章中我们将继续探索杰为软件Digital Thread的观点和技术——“创建一个统一的联邦语义网络模型,并将其扩展到数字工程&数字制造涉及的工具和存储库中”。
关注下期技术探索专辑,更多杰为Digital Thread产品和相关技术。